Plugins¶
One of the most useful aspects of the Girder platform is its ability to be extended in almost any way by custom plugins. Developers looking for information on writing their own plugins should see the Plugin Development section. Below is a listing and brief documentation of some of Girder’s standard plugins that come pre-packaged with the application.
Authorized Uploads¶
This plugin allows registered users to grant access to others to upload data on their behalf via a secure URL. The secure URL allows a third party to upload a single file into the selected folder, even if that third party does not have a registered user in Girder.
To authorize an upload on behalf of your user:
- Navigate into any folder to which you have write access. From the Folder actions dropdown menu on the right, choose Authorize upload here. You will be taken to a page that allows generation of a secure, single-use URL. You can optionally specify a number of days until the URL expires; if none is specified, the user session lifetime is used, which defaults to 180 days.
- Click Generate URL, and your secure URL will appear below.
- Copy that URL and send it to the third party, and they will be taken to a simple page allowing them to upload the file without having to see any details of the normal Girder application.
Note
When an upload is authorized, it’s authorized into a particular folder, and inherits the access control configured on that folder.
Jobs¶
The jobs plugin is useful for representing long-running (usually asynchronous) jobs in the Girder data model. Since the notion of tracking batch jobs is so common to many applications of Girder, this plugin is very generic and is meant to be an upstream dependency of more specialized plugins that actually create and execute the batch jobs.
The job resource that is the primary data type exposed by this plugin has many common and useful fields, including:
title: The name that will be displayed in the job management console.type: The type identifier for the job, used by downstream plugins opaquely.args: Ordered arguments of the job (a list).kwargs: Keyword arguments of the job (a dictionary).created: Timestamp when the job was createdprogress: Progress information about the job’s execution.status: The state of the job, e.g. Inactive, Running, Success.log: Log output from this job’s execution.handler: An opaque value used by downstream plugins to identify what should handle this job.meta: Any additional information about the job should be stored here by downstream plugins.
Jobs should be created with the createJob method of the job model. Downstream
plugins that are in charge of actually scheduling a job for execution should then
call scheduleJob, which triggers the jobs.schedule event with the job
document as the event info.
The jobs plugin contains several built-in status codes within the
girder.plugins.jobs.constants.JobStatus namespace. These codes represent
various states a job can be in, which are:
- INACTIVE (0)
- QUEUED (1)
- RUNNING (2)
- SUCCESS (3)
- ERROR (4)
- CANCELED (5)
Downstream plugins that wish to expose their own custom job statuses must hook
into the jobs.status.validate event for any new valid status value, which by convention
must be integer values. To validate a status code, the default must be prevented
on the event, and the handler must add a True response to the event. For example, a
downstream plugin with a custom job status with the value 1234 would add the following hook:
from girder import events
def validateJobStatus(event):
if event.info == 1234:
event.preventDefault().addResponse(True)
def load(info):
events.bind('jobs.status.validate', 'my_plugin', validateJobStatus):
Downstream plugins that want to hook into job updates must use a different convention than normal;
for the sake of optimizing data transfer, job updates do not occur using the normal save method
of Girder models. Therefore, plugins that want to listen to job updates should bind to either
jobs.job.update (which is triggered prior to persisting the updates and can be used to prevent
the update) or jobs.job.update.after (which is triggered after the update). Users of these events
should be aware that the log field of the job will not necessarily be in sync with the persisted
version, so if your event handler requires access to the job log, you should manually re-fetch the
full document in the handler.
Geospatial¶
The geospatial plugin enables the storage and querying of GeoJSON formatted geospatial data. It uses the underlying MongoDB support of geospatial indexes and query operators to create an API for the querying of items that either intersect a GeoJSON point, line, or polygon; are in proximity to a GeoJSON point; or are entirely within a GeoJSON polygon or circular region. In addition, new items may be created from GeoJSON features or feature collections. GeoJSON properties of the features are added to the created items as metadata.
The plugin requires the geojson Python package, which may be installed using pip:
pip install -e .[geospatial]
Once the package is installed, the plugin may be enabled via the admin console.
Google Analytics¶
The Google Analytics plugin enables the use of Google Analytics to track page views with the Girder one-page application. It is primarily a client-side plugin with the tracking ID stored in the database. Each routing change will trigger a page view event and the hierarchy widget has special handling (though it does not technically trigger routing events for hierarchy navigation).
To use this plugin, simply copy your tracking ID from Google Analytics into the plugin configuration page.
Homepage¶
The Homepage plugin allows the default Girder front page to be replaced by content written in Markdown format. After enabling this plugin, visit the plugin configuration page to edit and preview the Markdown.
Auto Join¶
The Auto Join plugin allows you to define rules to automatically assign new users to groups based on their email address domain. Typically, this is used in conjunction with email verification.
When a new user registers, each auto join rule is checked to see if the user’s email address contains the rule pattern as a substring (case insensitive).
If there is a match, the user is added to the group with the specified access level.
Download Statistics¶
This plugin tracks and records file download activity. The recorded information (downloads started, downloads completed, and total requests made) is stored on the file model:
file['downloadStatistics']['started']
file['downloadStatistics']['requested']
file['downloadStatistics']['completed']
DICOM Viewer¶
The DICOM Viewer plugin adds support for previewing DICOM files when viewing an item in girder. If multiple DICOM files are present in a single item, they are presented as multiple slices. The DICOM image is shown as well as a table of DICOM tags. The window center and width can be changed by the user. Controls allow the user to step through slices, auto-level the window, auto-zoom, or playback the slices at different speeds.
This plugin parses the DICOM tags when files are uploaded and stores them in the MongoDB database for quick retrieval. This is mostly used to sort multiple images by series and instance.
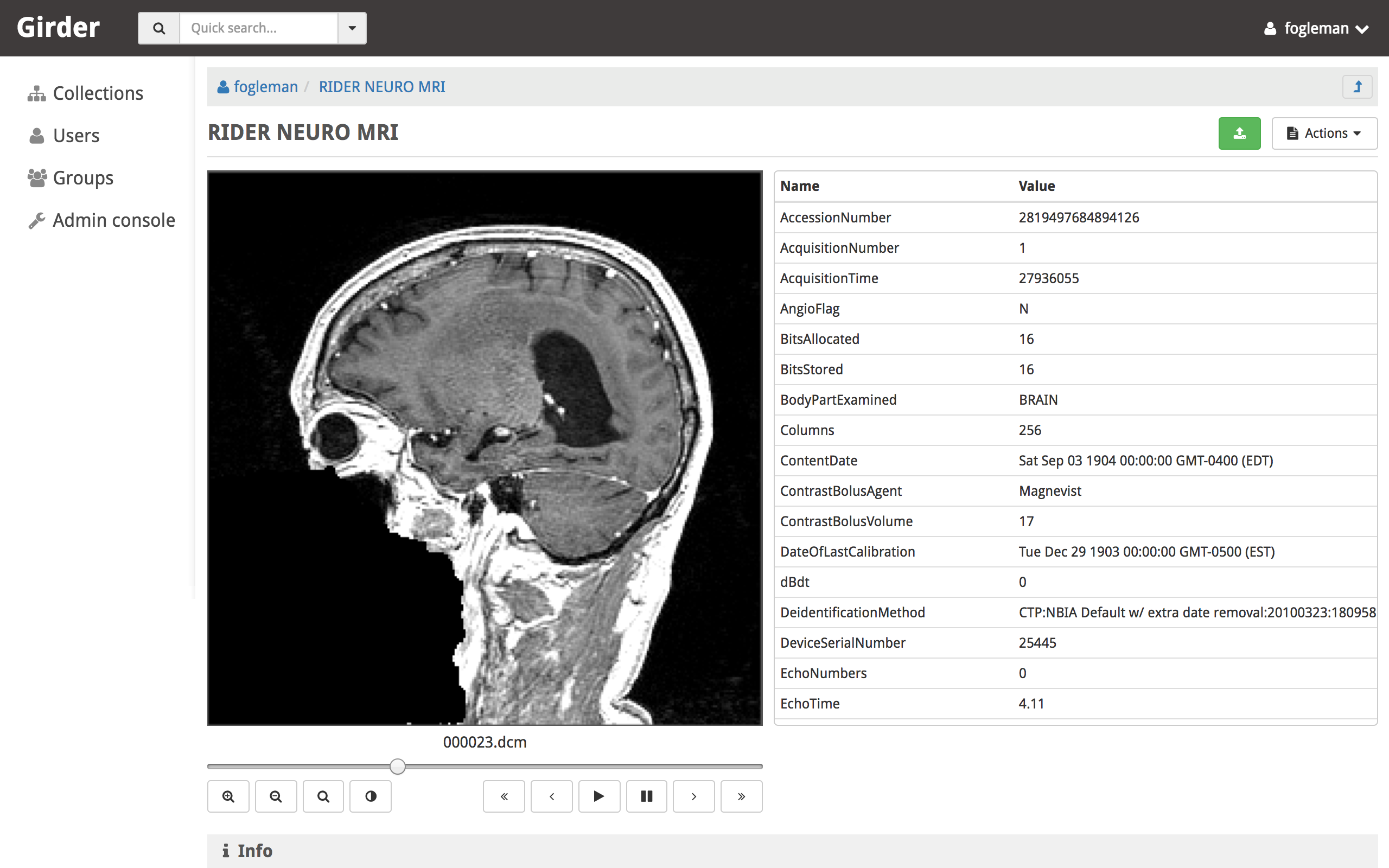
DICOM imagery from: https://wiki.cancerimagingarchive.net/display/Public/RIDER+NEURO+MRI
LDAP Authentication¶
This plugin allows administrators to configure the server so that users can log in against one or more LDAP servers. If the user fails to authenticate to any of the available LDAP servers, they will fall back to normal core authentication. Documentation of the LDAP standard in general can be found here.
Administrators can configure the ordered list of LDAP servers to try on the plugin configuration page. Each server in the list has several properties:
- URI: The URI of the LDAP server. Example:
ldaps://my.ldap.org:636. - Bind name: The Distinguished Name (DN) to use when connecting to the LDAP
server to perform directory searches. Example:
cn=me,cn=Users,dc=my,dc=ldap,dc=org. - Password: (Optional) The password to use when connecting to the LDAP server to perform directory searches.
- Base DN: The Distinguished Name (DN) under which to search for users
during login. Example:
cn=Users,dc=my,dc=ldap,dc=org. - Search field: (Optional) This specifies what field should be searched
in the directory for the login field entered by the user. The default value is
the
uidfield, though some implementations would want to use, e.g.mail. It is assumed that the search field will uniquely identify at most one user in the directory under the Base DN.
Note
This plugin is known to work against LDAP version 3. Using it with older versions of the protocol might work, but is not tested at this time.
Metadata Extractor¶
The metadata extractor plugin enables the extraction of metadata from uploaded files such as archives, images, and videos. It may be used as either a server-side plugin that extracts metadata on the server when a file is added to a filesystem asset store local to the server or as a remote client that extracts metadata from a file on a filesystem local to the client that is then sent to the server using the Girder Python client.
The server-side plugin requires several Hachoir Python packages to parse files and extract metadata from them. These packages may be installed using pip as follows:
pip install -e .[metadata_extractor]
Once the packages are installed, the plugin may be enabled via the admin console on the server.
In this example, we use the girder python client to
interact with the plugin’s python API.
Assuming girder_client.py and metadata_extractor.py are located in
the module path, the following code fragment will extract metadata from a file
located at path on the remote filesystem that has been uploaded to
itemId on the server:
from girder_client import GirderClient
from metadata_extractor import ClientMetadataExtractor
client = GirderClient(host='localhost', port=8080)
client.authenticate(login, password)
extractor = ClientMetadataExtractor(client, path, itemId)
extractor.extractMetadata()
The user authenticating with login and password must have WRITE
access to the file located at itemId on the server.
OAuth Login¶
This plugin allows users to log in using OAuth against a set of supported providers, rather than storing their credentials in the Girder instance. Specific instructions for each provider can be found below.
By using OAuth, Girder users can avoid registering a new user in Girder, leaving it up to the OAuth provider to store their password and provide details of their identity. The fact that a Girder user has logged in via an OAuth provider is stored in their user document instead of a password. OAuth users who need to authenticate with programmatic clients such as the girder-client python library should use API keys to do so.
Google¶
On the plugin configuration page, you must enter a Client ID and Client secret.
Those values can be created in the Google Developer Console, in the APIS & AUTH >
Credentials section. When you create a new Client ID, you must enter the
AUTHORIZED_JAVASCRIPT_ORIGINS and AUTHORIZED_REDIRECT_URI fields. These must
point back to your Girder instance. For example, if your Girder instance is hosted
at https://my.girder.com, then you should specify the following values:
AUTHORIZED_JAVASCRIPT_ORIGINS: https://my.girder.com
AUTHORIZED_REDIRECT_URI: https://my.girder.com/api/v1/oauth/google/callback
After successfully creating the Client ID, copy and paste the client ID and client secret values into the plugin’s configuration page, and hit Save. Users should then be able to log in with their Google account when they click the log in page and select the option to log in with Google.
Extension¶
This plugin can also be extended to do more than just login behavior using the OAuth providers. For instance, if you wanted some sort of integration with a user’s Google+ circles, you would add a custom scope that the user would have to authorize during the OAuth login process.
from girder.plugins.oauth.providers.google import Google
Google.addScopes(['https://www.googleapis.com/auth/plus.circles.read'])
Then, you can hook into the event of a user logging in via OAuth. You can hook in either before the Girder user login has occurred, or afterward. In our case, we want to do it after the Girder user has been fetched (or created, if this is the first time logging in with these OAuth credentials).
def readCircles(event):
# Read user's circles, do something with them
if event.info['provider'] == 'google':
token = event.info['token']
user = event.info['user']
...
from girder import events
events.bind('oauth.auth_callback.after', 'my_plugin', readCircles)
Curation¶
This plugin adds curation functionality to Girder, allowing content to be assembled and approved prior to publication. Admin users can activate curation for any folder, and users who are then granted permission can compose content under that folder. The users can request publication of the content when it is ready, which admins may approve or reject. The plugin provides a UI along with workflow management, notification, and permission support for these actions.
The standard curation workflow works as follows, with any operations affecting privacy or permissions being applied to the folder and all of its descendant folders.
- Site admins can enable curation for any folder, which changes the folder to Private.
- Users with write access can populate the folder with data.
- When ready, a user can request approval from the admin. The folder becomes read-only at this point for any user or group with write access, to avoid further changes being made while the admin is reviewing.
- The admin can approve or reject the folder contents.
- If approved, the folder becomes Public.
- If rejected, the folder becomes writeable again by any user or group with read access, enabling users to make changes and resubmit for approval.
The curation dialog is accessible from the Folder actions menu and shows the following information.
- Whether curation is enabled or disabled for the folder.
- The current curation status: construction, requested, or approved.
- A timeline of status changes, who performed them and when.
- Context-dependent action buttons to perform state transitions.
Provenance Tracker¶
The provenance tracker plugin logs changes to items and to any other resources that have been configured in the plugin settings. Each change record includes a version number, the old and new values of any changed information, the ID of the user that made the change, the current date and time, and the type of change that occurred.
API¶
Each resource that has provenance tracking has a rest endpoint of the form
(resource)/{id}/provenance. For instance, item metadata is accessible at
item/{id}/provenance. Without any other parameter, the most recent change
is reported.
The version parameter can be used to get any or all provenance information
for a resource. Every provenance record has a version number. For each
resource, these versions start at 1. If a positive number is specified for
version, the provenance record with the matching version is returned. If a
negative number is specified, the index is relative to the end of the list of
provenance records. That is, -1 is the most recent change, -2 the second most
recent, etc. A version of all returns a list of all provenance records
for the resource.
All provenance records include version, eventType (see below), and
eventTime. If the user who authorized the action is known, their ID is
stored in eventUser.
Provenance event types include:
creation: the resource was created.unknownHistory: the resource was created when the provenance plugin was disabled. Prior to this time, there is no provenance information.update: data, metadata, or plugin-related data has changed for the resource. The old values and new values of the data are recorded. Theoldparameter contains any value that was changed (the value prior to the change) or has been deleted. Thenewparameter contains any value that was changed or has been added.copy: the resource was copied. The original resource’s provenance is copied to the new record, and theoriginalIdindicates which record was used.
For item records, when a file belonging to that item is added, removed, or
updated, the provenance is updated with that change. This provenance includes
a file list with the changed file(s). Each entry in this list includes a
fileId for the associated file and one of these event types:
fileAdded: a file was added to the item. Thenewparameter has a summary of the file information, including its assetstore ID and value used to reference it within that assetstore.fileUpdate: a file’s name or other data has changed, or the contents of the file were replaced. Thenewandoldparameters contain the data values that were modified, deleted, or added.fileRemoved: a file was removed from the item. Theoldparameter has a summary of the file information. If this was the only item using this file data, the file is removed from the assetstore.
Gravatar Portraits¶
This lightweight plugin makes all users’ Gravatar image URLs available for use
in clients. When enabled, user documents sent through the REST API will contain
a new field gravatar_baseUrl if the value has been computed. If that field
is not set on the user document, instead use the URL /user/:id/gravatar under
the Girder API, which will compute and store the correct Gravatar URL, and then
redirect to it. The next time that user document is sent over the REST API,
it should contain the computed gravatar_baseUrl field.
Javascript clients¶
The Gravatar plugin’s javascript code extends the Girder web client’s girder.models.UserModel
by adding the getGravatarUrl(size) method that adheres to the above behavior
internally. You can use it on any user model with the _id field set, as in the following example:
import { getCurrentUser } from 'girder/auth';
const currentUser = getCurrentUser();
if (currentUser) {
this.$('div.gravatar-portrait').css(
'background-image', `url(${currentUser.getGravatarUrl(36)})`);
}
Note
Gravatar images are always square; the size parameter refers to
the side length of the desired image in pixels.
HDFS Assetstore¶
This plugin creates a new type of assetstore that can be used to store and proxy data on a Hadoop Distributed Filesystem. An HDFS assetstore can be used to import existing HDFS data hierarchies into the Girder data hierarchy, and it can also serve as a normal assetstore that stores and manages files created via Girder’s interface.
Note
Deleting files that were imported from existing HDFS files does not delete the original file from HDFS, they will simply be unlinked in the Girder hierarchy.
Once you enable the plugin, site administrators will be able to create and edit
HDFS assetstores on the Assetstores page in the web client in the same way
as any other assetstore type. When creating or editing an assetstore, validation
is performed to ensure that the HDFS instance is reachable for communication, and
that the directory specified as the root path exists. If it does not exist, Girder
will attempt to create it.
Importing data¶
Once you have created an HDFS assetstore, you will be able to import data into it on demand if you have site administrator privileges. In the assetstore list in the web client, you will see an Import button next to your HDFS assetstores that will allow you to import files or directories (recursively) from that HDFS instance into a Girder user, collection, or folder of your choice.
You should specify an absolute data path when importing; the root path that you chose for your assetstore is not used in the import process. Each directory imported will become a folder in Girder, and each file will become an item with a single file inside. Once imported, file data is proxied through Girder when being downloaded, but still must reside in the same location on HDFS.
Duplicates (that is, pre-existing files with the same name in the same location in the Girder hierarchy) will be ignored if, for instance, you import the same hierarchy into the same location twice in a row.
Remote Worker¶
This plugin should be enabled if you want to use the Girder worker distributed processing engine to execute batch jobs initiated by the server. This is useful for deploying service architectures that involve both data management and scalable offline processing. This plugin provides utilities for sending generic tasks to worker nodes for execution. The worker itself uses celery to manage the distribution of tasks, and builds in some useful Girder integrations on top of celery. Namely,
- Data management: This plugin provides python functions for building task input and output specs that refer to data stored on the Girder server, making it easy to run processing on specific folders, items, or files. The worker itself knows how to authenticate and download data from the server, and upload results back to it.
- Job management: This plugin depends on the Jobs plugin. Tasks are specified as python dictionaries inside of a job document and then scheduled via celery. The worker automatically updates the status of jobs as they are received and executed so that they can be monitored via the jobs UI in real time. If the script prints any logging information, it is automatically collected in the job log on the server, and if the script raises an exception, the job status is automatically set to an error state.
Item Tasks¶
This plugin integrates with the Girder worker and allows items in Girder’s data hierarchy to act as task specifications for the worker. In order to be used as a task specification, an item must expose two special metadata fields:
isItemTaskmust be set to indicate that this is an item task. The key must exist, but the value does not matter.itemTaskSpecmust be set to a JSON object representing the worker task specification. Documentation of valid worker task specifications can be found in the Girder worker documentation.
In order for users to run this task, they must be granted a special access flag granted on the containing folder, namely the Execute analyses flag exposed by this plugin. This special access flag can only be enabled by site administrators since the capabilities of items as tasks essentially enable arbitrary code execution on the worker nodes. Because of this power, administrators should be very careful of who has write access on folders where this permission flag is granted. It is strongly recommended for security reasons to isolate item tasks in folders separate from normal data, with minimal access granted to non-administrator users.
Once a user has this special access flag on item tasks, they will see the tasks appear in the list of available tasks when navigating to the Tasks view via the nav bar. They can also navigate to the item itself and use the Run this task option from the Actions menu. When they do so, they are prompted with an automatically-generated user interface allowing them to enter inputs to the task and output destinations, and then execute the task on the worker. The progress, status, and log output of the task is tracked in real-time via the jobs plugin. The input and output data for each execution of a task will also appear in that job details view, including links to any Girder data that was used as inputs or outputs.
Automatic configuration of item tasks via docker¶
Note
For security reasons, the capabilities in this section are only available to site administrators.
Many item tasks represent algorithms contained in docker images. Such docker images that implement self-describing behavior can be used to automatically populate an item task’s metadata fields. To auto-populate the task spec, navigate to an existing item that will be the item task, open the Actions menu, and select Configure task. A dialog will appear prompting the administrator to enter the docker image identifier and also specify any additional arguments needed to get the description output.
Note
Specifying the --xml argument is not necessary for Slicer Execution Model
docker task auto-configuration. If not included in the list, it is appended automatically.
Clicking Run will start a job on the worker to read the image’s description. The container is expected to write the description to standard output as a Slicer Execution Model XML document. When the job is finished, the task item specification should be set, and users should now be able to run the task represented by the docker image.
Note
The same item task can be auto-configured via docker multiple times without causing problems. Different image ids may be used each time if desired.
Hashsum Download¶
The hashum_download plugin allows a file to be downloaded from Girder given a hash value and hash algorithm. Use this plugin when you have large data that you don’t want to keep in a software repository, but want to access that data from the repository, e.g. during a build or test of that software project. This plugin is written to satisfy the needs of CMake ExternalData. These docs describe how to use this plugin along with ExternalData, but the plugin could be used outside of that context. For more detailed documentation on how to use this in a software repository see the ITKExamples. This example project uses the Girder instance https://data.kitware.com.
Note
The use of the hashsum_download plugin with CMake ExternalData is only supported with a filesystem assetstore and SHA512 as the hash algorithm.
As every local Git repository contains a copy of the entire project history, it is important to avoid adding large binary files directly to the repository. Large binary files added and removed throughout a project’s history will cause the repository to become bloated and take up too much disk space, requiring excessive time and bandwidth to download.
A solution to this problem, when using the CMake build system, is to store binary files in a separate location outside the Git repository, then download the files at build time with CMake.
CMake uses the notion of a content link file, which contains an identifying hash calculated from the original data file. The content link file has the same name as the data file, with a ”.sha512” extension appended to the file name, and should be stored in the Git repository. CMake will find these content link files at build time, download the corresponding data files from a list of server resources, and create symlinks or copies of the original files in the build tree, which is why the files are called “content links”.
What CMake calls a content link file, Girder calls a key file, as the notion of content link doesn’t apply in the context of Girder, and the hash value is a key into the original data file. When using the hashsum_download plugin, the data file is stored in Girder, with the SHA512 for the data added as metadata and provided as the key file, which can be downloaded from Girder and added to a project repository. The hashsum_plugin allows the data file to be downloaded based on the hash of the data. CMake ExternalData provides tooling to connect with a Girder instance, download the actual data file pointed to by the content link (key) file by passing the hash to Girder, and provide a local file path to access the data file contents.
Usage by a software project maintainer¶
Again, for more background, using the example Girder instance https://data.kitware.com, see the ITKExamples. Also see the CMake External Data documentation for CMake project configuration help.
In your project, you must set ExternalData_URL_TEMPLATES to a girder url, e.g. “https://data.kitware.com/api/v1/file/hashsum/%(algo)/%(hash)/download”.
See the ITK configuration for an example application of ExternalData_URL_TEMPLATES.
Project contributors will add data files to a Girder instance in arbitrary folders. At a project release and on a regular basis, perhaps nightly, the data should be archived in a new Girder folder to ensure its persistence. A script that provides this functionality is available, as is an example folder produced by the script for a release.
Usage by a software project contributor¶
Upload a file to a Girder instance, which will create a Girder Item to house the file. Navigate to the Item, then click on the i (information) icon next to the file, which will show the id, and since the hashsum_download plugin is enabled, the sha512 field will also be displayed. Click on the key icon to download a hashfile, which will be the full sha512 of the file, with the same name as the file, and an extension of .sha512, and you can use this key file as your CMake content link. E.g., upload my_datafile.txt and download the my_data.txt.sha512 file, then check the my_data.txt.sha512 file into your source repository.
You can use the Girder API to get the hash of the file given the file id, with the endpoint
api/v1/file/<file id>/hashsum_file/sha512, where the file id comes from the specific file in
Girder.
You can also use the API to download the file based on the hash returned by the previous endpoint,
with an endpoint /api/v1/file/hashsum/sha512/<file sha512 hash>/download, where the sha512 hash
comes from the specific file in Girder.